Log summary metrics
3 minute read
In addition to values that change over time during training, it is often important to track a single value that summarizes a model or a preprocessing step. Log this information in a W&B Run’s summary dictionary. A Run’s summary dictionary can handle numpy arrays, PyTorch tensors or TensorFlow tensors. When a value is one of these types we persist the entire tensor in a binary file and store high level metrics in the summary object, such as min, mean, variance, percentiles, and more.
The last value logged with wandb.log is automatically set as the summary dictionary in a W&B Run. If a summary metric dictionary is modified, the previous value is lost.
The proceeding code snippet demonstrates how to provide a custom summary metric to W&B:
wandb.init(config=args)
best_accuracy = 0
for epoch in range(1, args.epochs + 1):
test_loss, test_accuracy = test()
if test_accuracy > best_accuracy:
wandb.summary["best_accuracy"] = test_accuracy
best_accuracy = test_accuracy
You can update the summary attribute of an existing W&B Run after training has completed. Use the W&B Public API to update the summary attribute:
api = wandb.Api()
run = api.run("username/project/run_id")
run.summary["tensor"] = np.random.random(1000)
run.summary.update()
Customize summary metrics
Custom summary metrics are useful for capturing model performance at the best step of training in your wandb.summary. For example, you might want to capture the maximum accuracy or the minimum loss value, instead of the final value.
By default, the summary uses the final value from history. To customize summary metrics, pass the summary argument in define_metric. It accepts the following values:
"min""max""mean""best""last""none"
You can use "best" only when you also set the optional objective argument to "minimize" or "maximize".
The following example adds the min and max values of loss and accuracy to the summary:
import wandb
import random
random.seed(1)
wandb.init()
# Min and max summary values for loss
wandb.define_metric("loss", summary="min")
wandb.define_metric("loss", summary="max")
# Min and max summary values for accuracy
wandb.define_metric("acc", summary="min")
wandb.define_metric("acc", summary="max")
for i in range(10):
log_dict = {
"loss": random.uniform(0, 1 / (i + 1)),
"acc": random.uniform(1 / (i + 1), 1),
}
wandb.log(log_dict)
View summary metrics
View summary values in a run’s Overview page or the project’s runs table.
- Navigate to the W&B App.
- Select the Workspace tab.
- From the list of runs, click the name of the run that logged the summary values.
- Select the Overview tab.
- View the summary values in the Summary section.
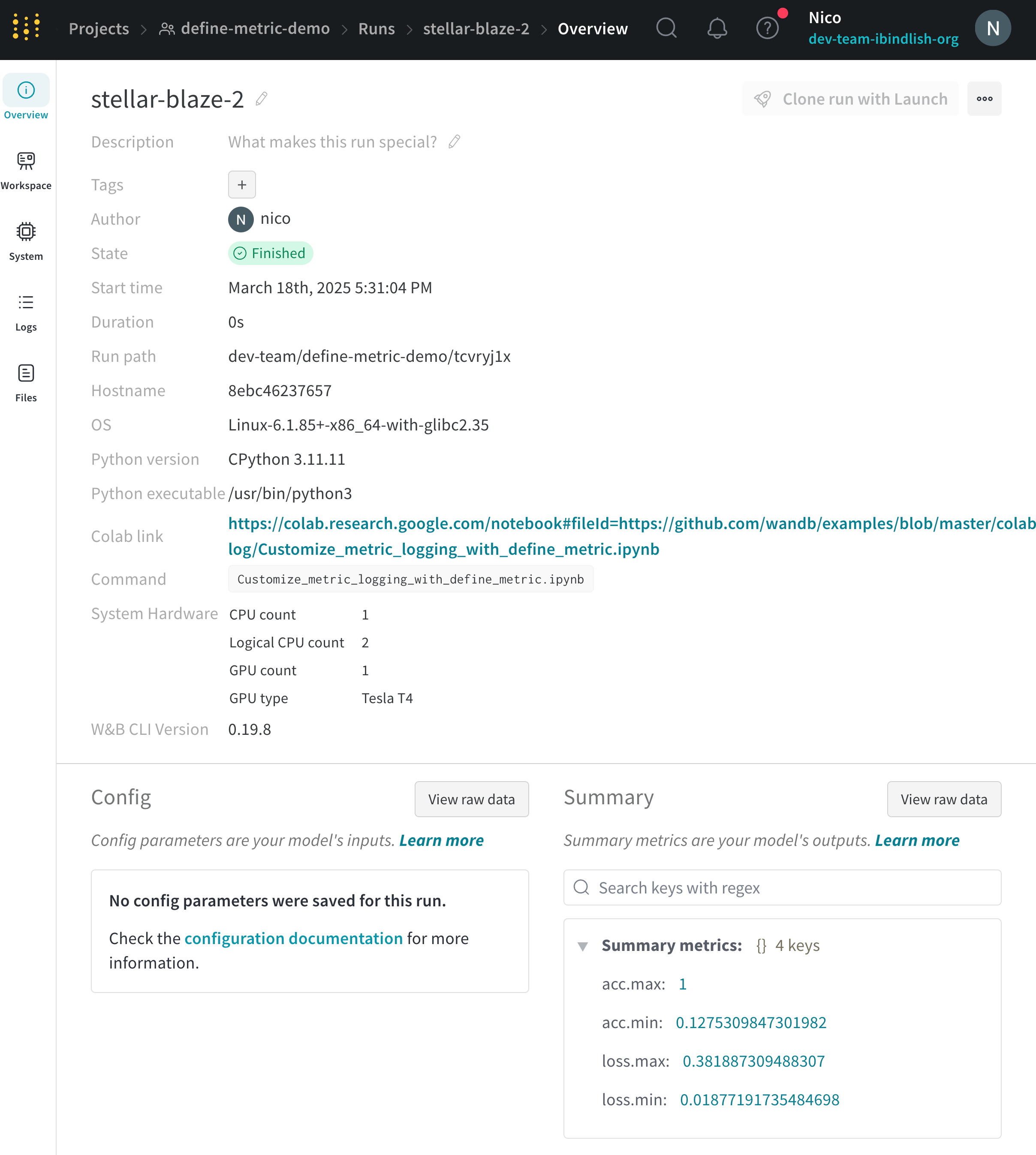
- Navigate to the W&B App.
- Select the Runs tab.
- Within the runs table, you can view the summary values within the columns based on the name of the summary value.
You can use the W&B Public API to fetch the summary values of a run.
The following code example demonstrates one way to retrieve the summary values logged to a specific run using the W&B Public API and pandas:
import wandb
import pandas
entity = "<your-entity>"
project = "<your-project>"
run_name = "<your-run-name>" # Name of run with summary values
all_runs = []
for run in api.runs(f"{entity}/{project_name}"):
print("Fetching details for run: ", run.id, run.name)
run_data = {
"id": run.id,
"name": run.name,
"url": run.url,
"state": run.state,
"tags": run.tags,
"config": run.config,
"created_at": run.created_at,
"system_metrics": run.system_metrics,
"summary": run.summary,
"project": run.project,
"entity": run.entity,
"user": run.user,
"path": run.path,
"notes": run.notes,
"read_only": run.read_only,
"history_keys": run.history_keys,
"metadata": run.metadata,
}
all_runs.append(run_data)
# Convert to DataFrame
df = pd.DataFrame(all_runs)
# Get row based on the column name (run) and convert to dictionary
df[df['name']==run_name].summary.reset_index(drop=True).to_dict()
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.